At NCX we rely heavily on our nation’s forest inventory program called the Forest Inventory and Analysis (FIA), a critical program run by the U.S. Forest Service. For years, we have been building tools to help us acquire and utilize the FIA data for our carbon and forestry modeling. We are pleased to announce that we have now open sourced fiadb, the python package we used to build and maintain our CONUS-wide copy of the Forest Inventory and Analysis (FIA) database. Our copy of the database is publicly accessible via the tidyFIA R package and is identical to the data that you can download from the FIA Datamart. As part of our effort to make our internal operations more transparent to the public, we are excited to share our method for making the FIA dataset more readily queryable. You are invited to use the package and make suggestions or code contributions. You can find the source code and an accompanying README here.
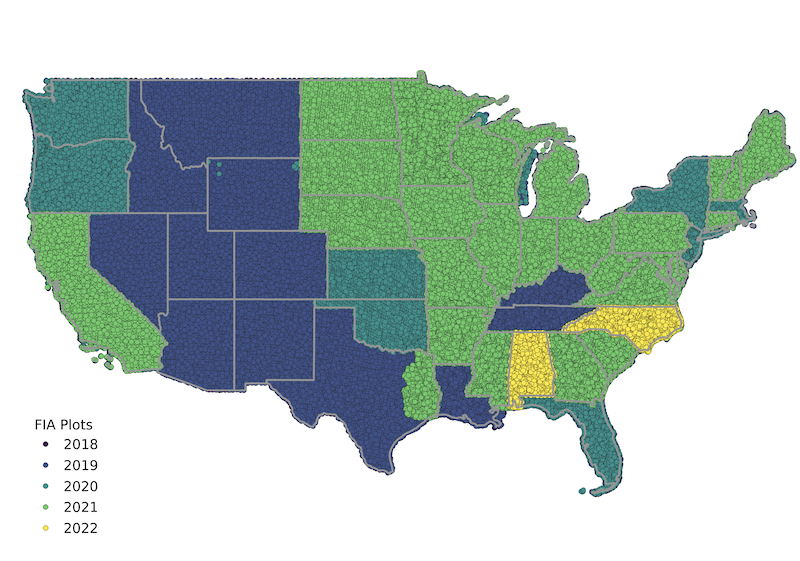
Map of recently measured FIA plots across the contiguous United States, created by connecting to NCX’s PostgreSQL clone of the FIA database via QGIS. The recency of the NCX copy can be compared to the map at the FIA Datamart
Why We Love the FIA Data
The FIA dataset is the single most extensive and rich forest vegetation dataset available in the United States, and it is a part of the bedrock of NCX. This publicly funded dataset is maintained by the USDA and helps countless public and private entities to make and evaluate land management decisions. Here are a few ways we have used the data over the years:
- Measurements of tree diameter and height inform species-specific local models for tree height, volume, and biomass.
- The most recently measured FIA plots are used to train our model for forest vegetation structure (Basemap).
- Repeated measurements (e.g. every five years) on FIA plots to provide rich insights into regional trends in timber harvesting across the country. These observations are an important component of our baseline disturbance and harvesting behavior models.
In order to protect private property rights and the integrity of the data, the FIA program protects the true plot locations by a process known as “fuzz and swap”, which means that the locations that are reported in the plot table do not represent the actual locations of the plots on the ground. Like everyone else, NCX only has access to this publicly available fuzzed dataset. Despite this spatial limitation, these data are still very valuable for our modeling and analysis of forest attributes in the US and we use them every single day.
The History of tidyFIA: an R Package for Rapid Access to FIA Data
As our use of the FIA data grew in frequency and scale, it became clear that we needed to invest in some tools to make it easier to get the data into an analysis-ready format. We built the tidyFIA R package to make the data-getting process easy for our internal projects, then we released it for public use in 2020. Originally, tidyFIA would take an area of interest and list of tables as input and download the relevant CSV files from the FIA Datamart. This process worked pretty well but it was slow and would fail when the files would occasionally become unavailable on the FIA Datamart site. To improve reliability and performance of the system we followed a guide published on the FIA Datamart for loading the CSV files into a PostgreSQL database with the PostGIS extensions. Hosting the data in a database running on Amazon Managed Relational Database Service (RDS) meant that we could rely on the data being available 24/7 without unpredictable interruptions. We would also have the ability to query the database using the PostGIS functions that makes it simple to pull data that corresponds to a specific geographic area. In April 2020 we made our original cloned FIA database available to the public via tidyFIA. We have since updated the database and continue to cover the cost of hosting it on AWS - check out the documentation for instructions on how to get up and running using the PostGIS database.
fiadb Revamp for More Reliable Data Loads
Our original method for loading the data into the database was fragile. The guide and accompanying SQL files were removed from the Datamart site and it quickly became clear that it was not a sustainable method for maintaining the database because it was already out of date with the latest database schema. For a while we lived with the database that we had installed originally, until Natasha Ravinand spent some time during her summer internship in 2021 working on a new method for populating the database. Natasha explored several options and settled on using pgloader to load a national SQLite snapshot into the PostgreSQL database. This process was effective but we found that the national snapshot was not updated very frequently and that it was difficult to download the entire file from the Datamart without an interruption. This winter I returned to the project and modified the process to work on the state-level SQLite files and to add some testing infrastructure. The result is a set of functions that can be used to load all of the available FIA data into a PostgreSQL database from a Python shell.
Next Steps
We have a few improvements that we will make in the future:
- Define a process for uploading only new records. Right now it is only possible to do a full clone, and update operations temporarily take the database down.
- Add continuous integration testing infrastructure to the tidyFIA package
- Host an interactive map of the FIA measurements for quick exploration of forest attributes
Please check out the new updates and let us know what you think (or if you’d like to contribute)! We believe transparency is a key ingredient for a successful voluntary carbon market and we strive to make our work more accessible.